(容量的に/個数的に)ボリュームのあるLOBをファイルへ一括出力して移動しようとすると、使うツールによってはとても遅い事があります。本稿はこのようなときに役立つMTUの機能について取り上げます。
MTUは大量のLOBを一括して扱うのに適したOCIの機能(*1)を採用する事で、データベースサーバーから離れた場所にあるコンピュータへ大量のLOBを高速に移動できるよう設計されています。
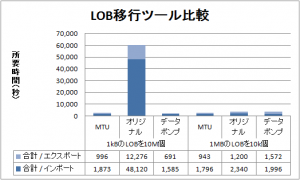
特に1kB未満の小さいLOBを多数(1000万個)移動するケースでは、オリジナルのエクスポート/インポートを使う場合と比べて約21倍も高速です。それ以外のケースでも、データポンプ・エクスポート/インポートを使う場合と同水準の性能を発揮する事が出来ます。
また、MTUから出力されるデータは同時に出力されるSQL*Loader用の制御ファイルと併せ、コマンド一つで再ロードする事が出来ます。加えてデータ表現がオープンであるため、Oracle Database 以外にもデータを提供できる点はエクスポート・ユーティリティーに無い特色と言えます。
本稿では、パーティショニングされたボリュームのあるLOB表を実際に用意し、LOBをファイルへ抽出する操作と、反対にファイルからLOBへデータを格納する操作(*2)を、MTU、オリジナルのエクスポート/インポート、及びデータポンプ・エクスポート/インポートの三者で行い、比較した結果をレポートします。
*1): LOB配列読取り(OCILobArrayRead 関数)、LOBデータ、長さおよびチャンク・サイズのプリフェッチ(OCI_ATTR_DEFAULT_LOBPREFETCH_SIZE)、それぞれOracle Database 10g Release 2及び11g から登場した新機能です。
*2): すべてのコマンドは実際に使われたもので、読者が手元に用意した環境を使って再現させる事が出来ます。
| 項目 | Oracle Database クライアント用 | Oracle Database サーバー用 |
|---|---|---|
| CPU | Intel Xeon(R) E5420 (2.50GHz) プロセッサ数1(コア数4) |
Intel Xeon(R) X3450 (2.67GHz) プロセッサ数1(コア数4) |
| RAM | 4GB | 12GB |
| HBA | SASアレイコントローラカード | Dell SAS 6/iR Adapter Controller |
| HDD | SAS 300GB/15000rpm×5 | SAS 500GB/15000rmp×2 |
| OS | Windows Server 2003 Stardard x64 Edition |
Windows Server 2008 R2 Standard x64 Edition |
create tablespace PAR1 datafile size 256m autoextend on next 32m maxsize unlimited; create tablespace PAR2 datafile size 256m autoextend on next 32m maxsize unlimited; create tablespace PAR3 datafile size 256m autoextend on next 32m maxsize unlimited; create tablespace PAR4 datafile size 256m autoextend on next 32m maxsize unlimited;
create or replace directory LOGICAL_BACKUP_DIR as 'C:\oracle\flash_recovery_area\o112utf8'; grant WRITE, READ on directory LOGICAL_BACKUP_DIR to SCOTT;
grant execute on DBMS_CRYPTO to public;
connect SCOTT/TIGER@o112utf8
create sequence TEST_PK_SQ minvalue 0 maxvalue 99999999 cycle cache 1000 start with 0;
create table CONTAINS_1K_10MLOBS ( PKEY number(8) , CLOB_HASH RAW(20) , CLOB_DATA CLOB , BLOB_HASH RAW(20) , BLOB_DATA BLOB , constraint PK_CONTAINS_1K_10MLOBS primary key (PKEY) ) lob (CLOB_DATA) store as (chunk 8k CACHE ENABLE STORAGE IN ROW) lob (BLOB_DATA) store as (chunk 8k CACHE ENABLE STORAGE IN ROW) partition by hash ( PKEY ) partitions 16 store in (PAR1, PAR2, PAR3, PAR4);
create table CONTAINS_1M_10KLOBS ( PKEY number(8) , CLOB_HASH RAW(20) , CLOB_DATA CLOB , BLOB_HASH RAW(20) , BLOB_DATA BLOB , constraint PK_CONTAINS_1M_10KLOBS primary key (PKEY) ) lob (CLOB_DATA) store as (chunk 32k CACHE DISABLE STORAGE IN ROW) lob (BLOB_DATA) store as (chunk 32k CACHE DISABLE STORAGE IN ROW) partition by hash ( PKEY ) partitions 16 store in (PAR1, PAR2, PAR3, PAR4);
set timing on serveroutput on size 999999 feedback off
declare
i binary_integer;
clob_tmp clob;
blob_tmp blob;
clob_prm clob;
blob_prm blob;
v_pkey binary_integer;
vc2_buf varchar2(32767);
raw_buf raw(32767);
begin
DBMS_RANDOM.INITIALIZE( 255 );
DBMS_LOB.CREATETEMPORARY(clob_tmp, TRUE, DBMS_LOB.CALL);
DBMS_LOB.CREATETEMPORARY(blob_tmp, TRUE, DBMS_LOB.CALL);
for i in 1 .. 1000000 loop
-- 1kB 前後のランダムなデータを作成(長さのバラつきは正規分布に従う)
for j in 1 .. 16 loop
vc2_buf := DBMS_RANDOM.STRING('A', DBMS_RANDOM.NORMAL*3.0 + 62) || chr(13) || chr(10);
raw_buf := UTL_RAW.CAST_TO_RAW(vc2_buf);
dbms_lob.writeappend(clob_tmp, length(vc2_buf), vc2_buf);
dbms_lob.writeappend(blob_tmp, UTL_RAW.LENGTH(raw_buf), raw_buf);
end loop;
INSERT INTO CONTAINS_1K_10MLOBS (PKEY, CLOB_DATA, BLOB_DATA)
VALUES (TEST_PK_SQ.nextval, EMPTY_CLOB(), EMPTY_BLOB())
RETURNING PKEY, CLOB_DATA, BLOB_DATA
INTO v_pkey, clob_prm, blob_prm;
DBMS_LOB.APPEND (clob_prm, clob_tmp);
DBMS_LOB.APPEND (blob_prm, blob_tmp);
UPDATE CONTAINS_1K_10MLOBS
SET CLOB_HASH = DBMS_CRYPTO.Hash(clob_prm, 1)
, BLOB_HASH = DBMS_CRYPTO.Hash(blob_prm, 1)
WHERE PKEY = v_pkey;
DBMS_LOB.TRIM(clob_tmp, 0);
DBMS_LOB.TRIM(blob_tmp, 0);
if mod(i, 10000) = 0 then
commit;
end if;
end loop;
end;
/
commit;
set timing on serveroutput on size 999999 feedback off
declare
i binary_integer;
clob_tmp clob;
blob_tmp blob;
clob_prm clob;
blob_prm blob;
v_pkey binary_integer;
vc2_buf varchar2(32767);
raw_buf raw(32767);
begin
DBMS_RANDOM.INITIALIZE( 255 );
DBMS_LOB.CREATETEMPORARY(clob_tmp, TRUE, DBMS_LOB.CALL);
DBMS_LOB.CREATETEMPORARY(blob_tmp, TRUE, DBMS_LOB.CALL);
for i in 1 .. 1000 loop
-- 1MB 前後のランダムなデータを作成(長さのバラつきは正規分布に従う)
for j in 1 .. 512 loop
vc2_buf := DBMS_RANDOM.STRING('A', DBMS_RANDOM.NORMAL*3.0 + 2046) || chr(13) || chr(10);
raw_buf := UTL_RAW.CAST_TO_RAW(vc2_buf);
dbms_lob.writeappend(clob_tmp, length(vc2_buf), vc2_buf);
dbms_lob.writeappend(blob_tmp, UTL_RAW.LENGTH(raw_buf), raw_buf);
end loop;
INSERT INTO CONTAINS_1M_10KLOBS (PKEY, CLOB_DATA, BLOB_DATA)
VALUES (TEST_PK_SQ.nextval, EMPTY_CLOB(), EMPTY_BLOB())
RETURNING PKEY, CLOB_DATA, BLOB_DATA
INTO v_pkey, clob_prm, blob_prm;
DBMS_LOB.APPEND (clob_prm, clob_tmp);
DBMS_LOB.APPEND (blob_prm, blob_tmp);
UPDATE CONTAINS_1M_10KLOBS
SET CLOB_HASH = DBMS_CRYPTO.Hash(clob_prm, 1)
, BLOB_HASH = DBMS_CRYPTO.Hash(blob_prm, 1)
WHERE PKEY = v_pkey;
DBMS_LOB.TRIM(clob_tmp, 0);
DBMS_LOB.TRIM(blob_tmp, 0);
if mod(i, 10) = 0 then
commit;
end if;
end loop;
end;
/
commit;
begin DBMS_STATS.GATHER_TABLE_STATS (USER, 'CONTAINS_1K_10MLOBS', degree=>dbms_stats.auto_degree); DBMS_STATS.GATHER_TABLE_STATS (USER, 'CONTAINS_1M_10KLOBS', degree=>dbms_stats.auto_degree); end; /
| 環境変数名 | 変更前 | 変更後 |
|---|---|---|
| USERID | SYSTEM/MANAGER | 接続先ユーザ名/パスワード@接続文字列 |
| DST_INFO | SCOTT/TIGER | SCOTT/TIGER@o112utf8 |
| LISTTABLE | (空) | CONTAINS_1K_10MLOBS |
| FILESIZE | 2000M | 0M |
| USUALPATH | true | (空) |
| RECOVERABLE | true | (空) |
| MERGE_LOBS_INTO_SDF | (空) | true |
| PARALLELISM | 4 | 8 |
| PARTITIONING | 3 | 0 |
所要時間や出力されたファイルのバイト数を記録します。
declare cursor c1 is select * from CONTAINS_1K_10MLOBS/ * 所要時間 4 分 12 秒 */ /*CONTAINS_1M_10KLOBS*/ /* 所要時間 17 分 34 秒 */ ; clob_unmatched binary_integer; blob_unmatched binary_integer; clob_matched binary_integer; blob_matched binary_integer; clob_is_null binary_integer; blob_is_null binary_integer; begin clob_unmatched := 0; blob_unmatched := 0; clob_matched := 0; blob_matched := 0; clob_is_null := 0; blob_is_null := 0; for r1 in c1 loop if r1.CLOB_DATA is not null then if r1.CLOB_HASH <> DBMS_CRYPTO.Hash(r1.CLOB_DATA, 1) then clob_unmatched := clob_unmatched + 1; else clob_matched := clob_matched + 1; end if; else clob_is_null := clob_is_null + 1; end if; if r1.BLOB_DATA is not null then if r1.BLOB_HASH <> DBMS_CRYPTO.Hash(r1.BLOB_DATA, 1) then blob_unmatched := blob_unmatched + 1; else blob_matched := blob_matched + 1; end if; else blob_is_null := blob_is_null + 1; end if; end loop; dbms_output.put_line( 'clob_unmatched='|| to_char(clob_unmatched,'fm999,999,999') || ', clob_matched=' || to_char(clob_matched,'fm999,999,999') || ', clob_is_null=' || to_char(clob_is_null,'fm999,999,999') ); dbms_output.put_line( 'blob_unmatched='|| to_char(blob_unmatched,'fm999,999,999') || ', blob_matched=' || to_char(blob_matched,'fm999,999,999') || ', blob_is_null=' || to_char(blob_is_null,'fm999,999,999') ); end; /
| 環境変数名 | 変更前 | 変更後 |
|---|---|---|
| LISTTABLE | CONTAINS_1K_10MLOBS | CONTAINS_1M_10KLOBS |
所要時間や出力されたファイルのバイト数を記録します。
declare cursor c1 is select * from /*CONTAINS_1K_10MLOBS*//* 所要時間 4 分 12 秒 */ CONTAINS_1M_10KLOBS /* 所要時間 17 分 34 秒 */ ; clob_unmatched binary_integer; blob_unmatched binary_integer; clob_matched binary_integer; blob_matched binary_integer; clob_is_null binary_integer; blob_is_null binary_integer; begin clob_unmatched := 0; blob_unmatched := 0; clob_matched := 0; blob_matched := 0; clob_is_null := 0; blob_is_null := 0; for r1 in c1 loop if r1.CLOB_DATA is not null then if r1.CLOB_HASH <> DBMS_CRYPTO.Hash(r1.CLOB_DATA, 1) then clob_unmatched := clob_unmatched + 1; else clob_matched := clob_matched + 1; end if; else clob_is_null := clob_is_null + 1; end if; if r1.BLOB_DATA is not null then if r1.BLOB_HASH <> DBMS_CRYPTO.Hash(r1.BLOB_DATA, 1) then blob_unmatched := blob_unmatched + 1; else blob_matched := blob_matched + 1; end if; else blob_is_null := blob_is_null + 1; end if; end loop; dbms_output.put_line( 'clob_unmatched='|| to_char(clob_unmatched,'fm999,999,999') || ', clob_matched=' || to_char(clob_matched,'fm999,999,999') || ', clob_is_null=' || to_char(clob_is_null,'fm999,999,999') ); dbms_output.put_line( 'blob_unmatched='|| to_char(blob_unmatched,'fm999,999,999') || ', blob_matched=' || to_char(blob_matched,'fm999,999,999') || ', blob_is_null=' || to_char(blob_is_null,'fm999,999,999') ); end; /
エクスポート・インポートユーティリティーに使用したパラメータファイルは次の通りです。
| ユーティリティー | CONTAINS_1K_10MLOBS | CONTAINS_1M_10KLOBS |
|---|---|---|
| オリジナルのエクスポート | userid=SCOTT/TIGER@o112utf8 tables=CONTAINS_1K_10MLOBS file=%OUTPUT%\CONTAINS_1K_10MLOBS log=%OUTPUT%\CONTAINS_1K_10MLOBS_exp buffer=5000000 direct=y |
userid=SCOTT/TIGER@o112utf8 tables=CONTAINS_1M_10KLOBS file=%OUTPUT%\CONTAINS_1M_10KLOBS log=%OUTPUT%\CONTAINS_1M_10KLOBS_exp buffer=5000000 direct=y |
| オリジナルのインポート | userid=SCOTT/TIGER@o112utf8 tables=CONTAINS_1K_10MLOBS file=%OUTPUT%\CONTAINS_1K_10MLOBS log=%OUTPUT%\CONTAINS_1K_10MLOBS_imp buffer=5000000 commit=y |
userid=SCOTT/TIGER@o112utf8 tables=CONTAINS_1M_10KLOBS file=%OUTPUT%\CONTAINS_1M_10KLOBS log=%OUTPUT%\CONTAINS_1M_10KLOBS_imp buffer=5000000 commit=y |
| データポンプ・エクスポート | USERID=SCOTT/TIGER@o112utf8 DIRECTORY=LOGICAL_BACKUP_DIR ESTIMATE=STATISTICS TABLES=CONTAINS_1K_10MLOBS LOGFILE=CONTAINS_1K_10MLOBS_expdp DUMPFILE=CONTAINS_1K_10MLOBS_%U PARALLEL=8 |
USERID=SCOTT/TIGER@o112utf8 DIRECTORY=LOGICAL_BACKUP_DIR ESTIMATE=STATISTICS TABLES=CONTAINS_1M_10KLOBS LOGFILE=CONTAINS_1M_10KLOBS_expdp DUMPFILE=CONTAINS_1M_10KLOBS_%U PARALLEL=8 |
| データポンプ・インポート | USERID=SCOTT/TIGER@o112utf8 DIRECTORY=LOGICAL_BACKUP_DIR TABLES=CONTAINS_1K_10MLOBS LOGFILE=CONTAINS_1K_10MLOBS_impdp DUMPFILE=CONTAINS_1K_10MLOBS_%U PARALLEL=8 |
USERID=SCOTT/TIGER@o112utf8 DIRECTORY=LOGICAL_BACKUP_DIR TABLES=CONTAINS_1M_10KLOBS LOGFILE=CONTAINS_1M_10KLOBS_impdp DUMPFILE=CONTAINS_1M_10KLOBS_%U PARALLEL=8 |
by 開発1号